

리턴제로에서 서버팀을 맡고있는 Castor입니다. 저희가 서비스를 런칭한지 2년이 넘었는데요, 그동안 VITO 서비스를 안정권에 올려 놓느라 저희 팀의 기술 블로그를 적을 시간과 정신이 없었습니다. 그래서 이제부터 리턴제로의 자랑스런 기술력에 대해 글을 적기 위해 제가 이렇게 첫 삽을 뜨게 되었습니다.
먼저 VITO 서비스의 CI/CD 변천사에 대한 시리즈로 출발하겠습니다. 많은 스타트업들이 그렇듯이 VITO 또한 서비스를 준비하고, 런칭하고, 운영하고, 키워나가는 과정 속에서 시스템의 많은 변화가 있었습니다. 그래서 VITO 서비스를 준비하던 2020년 초반부터 서비스를 키워 나가면서 있었던 CI/CD의 변화를 적어보려고 합니다.
VITO 서비스의 이해
VITO 서비스는 크게 '일반적인 API 서비스' 부분과 음성파일을 문자로 변환시키기 위해서 여러개의 처리 서비스를 묶어서 부르는 'Sommers'라는(ML) 부분으로 나뉘어져 있습니다.

먼저 user가 문자로 변환을 원하는 파일을 API서버를 통해서 upload하게 되면 해당 음성파일을 리턴제로에서 독자 개발한 Sommers라는 전사시스템으로 전송하게 됩니다.
여기서 전사의 의미에 대해 간략히 적어보자면, 다음과 같습니다.
전사 (轉寫)[명사]
1. 글이나 그림 따위를 옮기어 베낌.
2. 말소리를 음성 문자로 옮겨 적음.
Sommers는 여러 서비스로 구성된 파이프라인을 지나 변환된 문자를 VITO앱으로 다시 돌려주는 역할을 합니다.
서비스의 시작
서비스를 오픈하는 시점에 CI/CD를 어떻게 구성 해야하는지에 대해 상당한 고민을 하게 되었습니다. 단순히 AWS EC2의 auto scale을 활용해서 template화 시켜야 할지, 처음부터 k8s를 잘 셋팅해서 할지, 아니면 아에 모든것을 손으로 컨트롤 하면서 운영할지 고민을 할 수 밖에 없었습니다. 왜냐면 초기에는 사용자가 몇 명 안될 것이고, 이 사용자들이 어떻게 늘어날 지는 예측하기 힘들기 때문입니다.
일단 처음 구성은 개발자가 즉각적으로 대응 하기 쉬운 형태로 배포 시스템을 구성 하기로 했습니다. 바로 '손스케일링'입니다. 손스케일링을 하려다보니 직접적으로 시스템을 파악하기 쉽고 인스턴스 내부에 직접 접근해서 여러가지 설정들을 수동으로 바꿀 수 있는 구조가 필요했습니다. 그래서 저희는 ECS나 EKS같은 Cloud service를 구성하지 않고 서버들을 직접적으로 투입하고 빼는 작업을 Jenkins의 pipeline이 AWS cli 명령이나 Ansible script로 실행하게 되었습니다. 이렇게 하면 이슈가 있는 서버에 콘솔로 바로 접근해서 어떤 일들이 일어나고있는지 빠르게 파악할 수 있기 때문입니다. 사실 바꿔 말하면 Cloud service에 익숙치 않았다고 해야할까요.
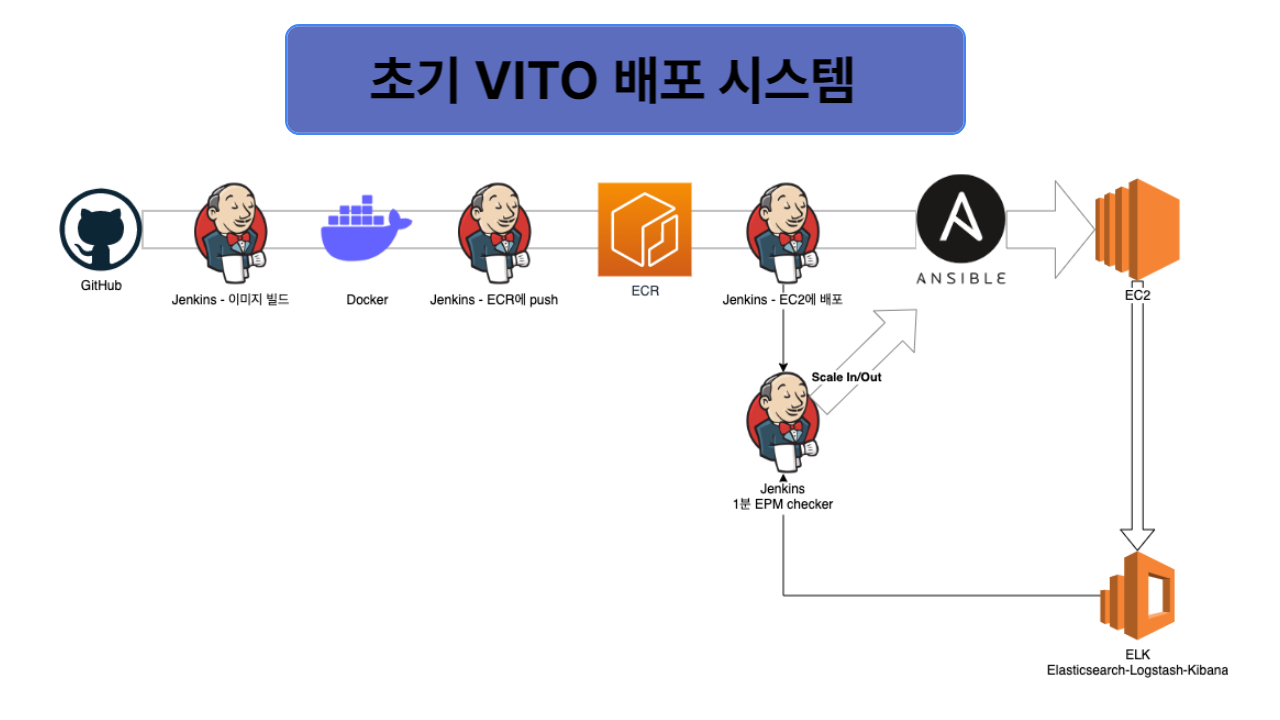
AutoScale의 기준
Sommers 시스템은 4~5개의 서비스를 묶어서 지칭하는 서비스명입니다. 그래서 각 구간별로 투입되어야 하는 서버의 스팩과 투입되는 대수가 상이합니다. 또 어떤 구간에서는 GPU를 쓰지 않는 구간도 있기 때문에 하나의 서비스를 구성하는데 있어서 어떤 구간에서 밀리고 있는지 파악하고 해당 구간만 적절하고 빠르게 늘려주면 아주 아름다운 AutoScale이 완성이 될 것이라고 상상했습니다. 왜냐하면 간단히 생각하면 그냥 MicroService Architecture와 다를게 없거든요. 하지만 현실은 상상과 달랐습니다.
Sommers 시스템의 특수성 - 서비스 투입시간
Sommers 시스템은 GPU가 사용되기 때문에 GPU instance인 g4 instance를 주로 사용하고 있는데요. 음성처리에서 많이 쓰이는 Kaldi, TensorFlow(이하 tf)들도 모두 GPU를 사용합니다. 일반적인 CPU instance들은 scale out시에 수초~1분정도안에는 scale out이 완료되고 docker image를 load하고 서비스에 투입됩니다. 하지만 Sommers 시스템들은 모두 warm up과 model을 로딩하는데 5분 혹은 30분까지도 딜레이가 생겼습니다. 이 때문에 트래픽이 몰리거나 통화녹음 파일이 많은 헤비유저가 녹음파일을 대량으로 업로드 할 경우에는 속절없이 30분 가까이 큐가 차는 모습을 지켜보고 있어야 했습니다.

Sommers 시스템의 특수성 - System지표
보통의 Scale in/out은 cpu, memory, network사용량등을 보고 결정을 하게 되는데 GPU를 사용하는 Sommers의 GPU 지표는 언제나 100%에 육박해 있습니다.

그렇기 때문에 시스템 지표를 통해서는 scale in/out에 대한 기준을 잡을 수가 없어서, 결국 문자변환을 기다리는 큐가 얼마나 차 있느냐를 보고 미리 scale out을 해야 이후에 몰려오는 전사요청을 처리할 수 있게 됩니다.
EPM(Enqueue per Minute)
처음에는 Sommers의 각 서비스들의 각각의 대기큐를 보면서 밀리는 서비스가 생기면 해당 서비스만 추가로 투입하고 빼는 형태로 구성했습니다. 예를 들어, 음성 파일을 처리하는 Sommers pipeline이 A->B->C->D 서비스로 구성되어있다면 B구간에서 밀려서 큐가 찬다고 해서 B만 늘리면 B가 해소되면서 동시에 C가 밀리고 C를 늘리면 또 D가 밀리게 됩니다. 결국 트래픽이 많을 때 각 구간별로 세세하게 scale하는 것이 의미가 없어졌습니다. 그래서 저희는 각 서비스의 최적의 비율을 정해서 해당 비율을 하나의 Set으로 부르고, RabbitMQ에 enqueue되는 양을 1분마다 측정해서 해당 측정치를 EPM으로 불렀습니다. 그리고 나서 EPM이 특정 구간에 도달하면 하나의 Set씩 통째로 scale in/out 하도록 구성했습니다.
Container Ochestration의 시대로
이렇게 저희가 직접 scale되는 것들을 운영하다보니 점점 Jenkins의 Groovy script, Ansible script가 복잡해져가고 운영 코스트가 증가하기 시작했습니다. 그렇게 백엔드 개발자 두명이서 고군분투 중일때 저희 팀의 구원자 Owen이 입사를 하게 되었습니다. 저희 배포 시스템의 복잡성을 탄식하던 Owen은 배포 시스템을 뒤엎기로 결정합니다.
오늘의 이야기는 여기서 마치도록 하겠습니다. Container Ochestration의 시대로 넘어가는 다음 이야기를 기대해주세요.
눈으로보는 통화
무료 STT API 제공
'AI 이야기' 카테고리의 다른 글
| VITO CI/CD 변천사 두번째 - Container Orchestration (0) | 2022.08.31 |
|---|---|
| [AI뉴스] 누구나 간편하게 딥페이크 영상 만들기 (0) | 2022.08.30 |
| [AI뉴스] 2020년 AI 핫이슈 베스트 5 (0) | 2022.08.25 |
| 음성인식 API 비토 스피치(VITO Speech) (0) | 2022.08.18 |
| 앱 내 전화에 음성인식 이용하여 리텐션 높이기 (0) | 2022.08.17 |




댓글